n8n em Kubernetes: Arquitetura de referência para Alta Disponibilidade
Rodar n8n no Docker Compose é fácil. Escalar em Kubernetes sem perder execuções é outra história. Descubra a arquitetura de referência que separa ambientes de teste de operações *enterprise* resilientes.
Há uma frase famosa que diz: "A esperança não é uma estratégia".
Muitas empresas começam a usar o n8n em uma instância EC2 simples ou um Droplet, rodando via Docker Compose com o banco SQLite padrão. Funciona maravilhosamente bem... até não funcionar mais.
O problema geralmente surge da mesma forma: um pico de tráfego na Black Friday, um workflow mal otimizado que consome toda a RAM, ou um travamento no banco de dados SQLite que corrompe o arquivo de execução. O servidor cai, o n8n reinicia, e você perdeu dados críticos.
Se o n8n se tornou missão crítica para sua empresa, você precisa parar de tratá-lo como um script e começar a tratá-lo como uma aplicação distribuída. Vamos falar sobre como arquitetar isso no Kubernetes.
O Adeus ao Monolito: Entendendo o Queue Mode
A documentação oficial do n8n é clara, mas muitas vezes ignorada: para escala, você precisa migrar para o Queue Mode.
No Docker Compose padrão, o n8n é um monolito. Ele recebe o webhook, processa a lógica e escreve no banco. Se o processamento trava, o webhook cai.
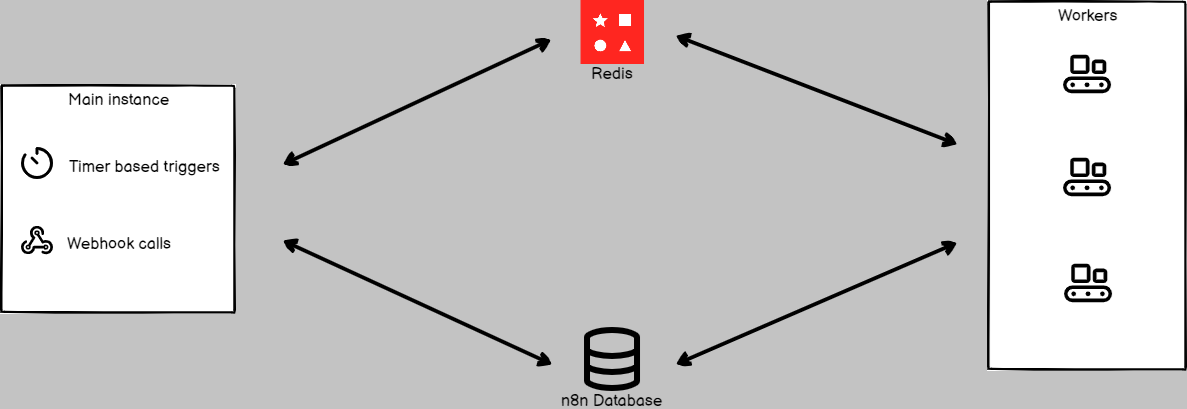
Na arquitetura de Alta Disponibilidade (HA) no Kubernetes, desacoplamos essas funções seguindo metodologias modernas, como os princípios do The Twelve-Factor App. A arquitetura de referência que implementamos na n8nscale divide o n8n em três componentes vitais:
- Main/Editor Pod: Serve apenas a interface do usuário (UI) e a API de gestão. Se ele cair, seus workflows continuam rodando.
- Webhook Scalers: Pods leves, focados apenas em receber requisições HTTP e jogá-las rapidamente para o Redis. Eles escalam horizontalmente com facilidade para aguentar milhares de requests por segundo.
- Workers: Os operários pesados. Eles lêem as mensagens do Redis e executam o trabalho duro.
O Coração da Resiliência: Redis e PostgreSQL
Esqueça o SQLite. Em um ambiente clusterizado, tentar usar SQLite é pedir para ter corrupção de dados (mesmo com volumes persistentes, o lock do banco vai te trair).
A arquitetura robusta exige:
- PostgreSQL: Para armazenar o histórico de execuções, credenciais e definições de workflows. Utilize serviços gerenciados (como Amazon RDS ou Azure SQL) para garantir backups e failover automático.
- Redis: Atua como o message broker. É ele quem garante que, se um Worker morrer no meio do processo, a mensagem não foi perdida (dependendo da configuração de persistência) ou, no mínimo, desacopla a ingestão do processamento.
O Desafio dos Arquivos Binários
Aqui está a "pegadinha" que pega muitos de surpresa ao migrar para Kubernetes. O n8n, por padrão, salva arquivos binários (aquele PDF que você baixou no workflow) no disco local.
Se o Webhook Pod baixa o arquivo e o Worker Pod tenta processá-lo, o Worker vai falhar porque o arquivo não está no disco dele.
Existem duas soluções, mas apenas uma recomendada para Cloud Native:
- Shared Volumes (NFS/EFS): Funciona, mas é lento e pode causar gargalos de I/O.
- Object Storage (S3/Azure Blob): A solução correta. Configure o n8n para externalizar o armazenamento de binários diretamente para um bucket S3. Isso torna seus pods stateless (sem estado), permitindo que eles morram e renasçam sem perder dados.
Autoscaling Inteligente com KEDA
Não basta definir um replicas: 3 no seu deployment. O verdadeiro poder do Kubernetes brilha quando usamos KEDA (Kubernetes Event-driven Autoscaling).
Ao invés de escalar seus Workers baseado apenas em uso de CPU (o que é reativo e lento), configuramos o KEDA para monitorar a lista do Redis.
- Lista vazia? Reduz para 1 (ou 0) workers para economizar dinheiro.
- 1.000 itens na fila? O KEDA sobe instantaneamente 20, 50, 100 workers para processar o backlog e depois mata os pods quando o trabalho termina.
Conclusão
Migrar o n8n para Kubernetes não é apenas um "Lift and Shift". É uma mudança de mentalidade de servidor único para sistemas distribuídos.
Essa arquitetura elimina o ponto único de falha, garante que picos de tráfego não derrubem sua operação e permite atualizações sem downtime.
Parece complexo? É porque é. Se sua equipe precisa focar na lógica de negócio e não em configurar Ingress Controllers, Redis Sentinels e manifestos YAML, a n8nscale pode implementar essa arquitetura de referência na sua nuvem. Vamos conversar?
Comentários
Nenhum comentário ainda. Seja o primeiro a comentar!